How We Rate Article Bias
Explanation
Bias Rating
This article is neutral on this stock. That means the author expects the stock to hold in value

This article is bullish on this stock. That means the author expects the stock to rise in value

This article is bearish on this stock. That means the author expects the stock to fall in value

Expectation Unknown

How We Determine Bias Rating
Nobias processes thousands of articles every day and uses machine learning to determine whether an article is bullish or bearish.
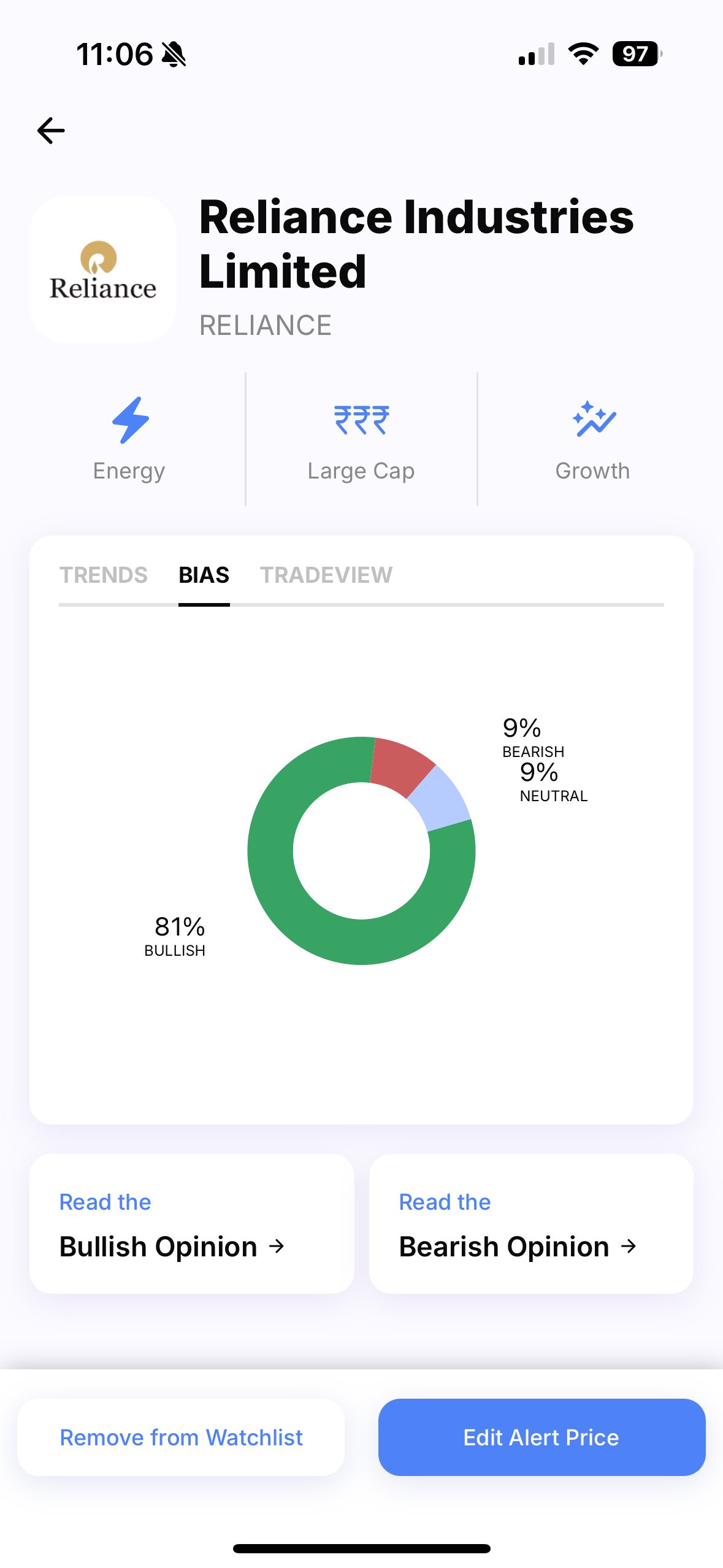
We also zoom out and give you context on the overall market sentiment for a particular stock. Let’s see how we break this down.
You can see in the image that we highlight the sentiment of the article about Reliance being bullish. We also show you in the donut chart on the top right the distribution of sentiments across all articles written on Reliance India—this is the market sentiment. Hover over the segments to view how many articles are written on each side.
To obtain our bias rating, we employ proprietary Natural Language Processing (NLP) and Deep Learning methods, built on Nobias’ own and the latest research in Machine Learning.
How We Determine Credibility Rating
Nobias processes thousands of articles every day and tracks the performance of the analysts and bloggers you read using unbiased, transparent methodologies. We want you to decide for yourself who to trust.
Let’s see how we break this down.
As shown in the image, this analyst is ranked #181 in our database of 2773 analysts and bloggers. She has been accurate 61% of the time. If you followed all of her recommendations over three months, you would have an average return of approximately 9%.
All of this results in a “CREDIBLE AUTHOR” credibility rating for this author. We determine our stars using a combination of:
Accuracy Rate: The percent of their recommendations that were correct three months following publication.
Average Expected Return: The expected return of the author’s recommendation in the 3-month period (for bloggers) or in a 1-year period (for analysts) following publication.
Downside: This is the maximum loss experienced during the 3-month period (for bloggers) or in a 1-year period (for analysts) following publishing.
The number of articles an author has written.

How We Determine Fund Ranking
Nobias employs a systematic and algorithm-based approach to research and score mutual fund schemes. Our research process consists of multiple steps, which we will describe below:
STEP 1 - Key Return & Ratio Analysis
To assess equity mutual fund schemes, we start by analysing its key ratios on performance, cost and risk based on all available data dating back to the inception of the fund
Performance:
5, 3 and 1 year rolling returns
10, 5 and 3 year CAGR
Cost
Expense Ratio
Fund specific information
Fund Tenure
Risk:
Sharpe Ratio
Measures investment return relative to its volatility, indicating how much excess return an investor receives for taking on additional risk.
Sortino Ratio
Similar to Sharpe Ratio, but focuses solely on downside risk, providing a better assessment of an investment's performance in unfavourable conditions.
Treynor Ratio
Evaluates investment return adjusted for systematic (market-related) risk, helping investors compare investments based on their sensitivity to market movements.
When these ratios consistently show better performance over an extended period, they receive higher scores
STEP 2 - Fund House Analysis
We conduct a fund house analysis to evaluate their past performance, considering their management of all their funds. This assessment includes:
A performance score based on the performance of all funds managed by the fund house.
The fund house’s cumulative experience in managing funds.
The fund house's score on grievance reddressal.
STEP 3 - Final Score Calculation
The final scores are derived from the amalgamation of the Fund Score and Fund Manager Score. Mutual fund schemes are scored on a scale of 0 to 100, with 100 being the highest score and 0 being the lowest.
STEP 4 - Ranking
Rankings are determined by assessing the final scores of the funds, thereby showcasing their relative standings within their respective categories.
Note - The Nobias scoring and ranking model is updated quarterly. We analyse all equity category funds with a track record of more than 5 years.
This comprehensive and systematic approach ensures that our evaluations are based on up-to-date data, aiding investors in making well-informed decisions.
Dive Deeper Into Our Bias Ratings
Background
BERT (Bidirectional Encoder Representations from Transformers) is a recent paper published by researchers at Google AI Language. BERT’s key technical innovation is applying the bidirectional training of Transformer, a popular attention model, to language modelling. This is in contrast to previous efforts which looked at a text sequence either from left to right or combined left-to-right and right-to-left training.
How it works
BERT makes use of Transformer, an attention mechanism that learns contextual relations between words (or sub-words) in a text. In its vanilla form, Transformer includes two separate mechanisms – an encoder that reads the text input and a decoder that produces a prediction for the task. Since BERT’s goal is to generate a language model, only the encoder mechanism is necessary. The chart below is a high-level description of the Transformer encoder. The input is a sequence of tokens, which are first embedded into vectors and then processed in the neural network. The output is a sequence of vectors of size H, in which each vector corresponds to an input token with the same index.

Dive Deeper Into Our Analyst Ratings
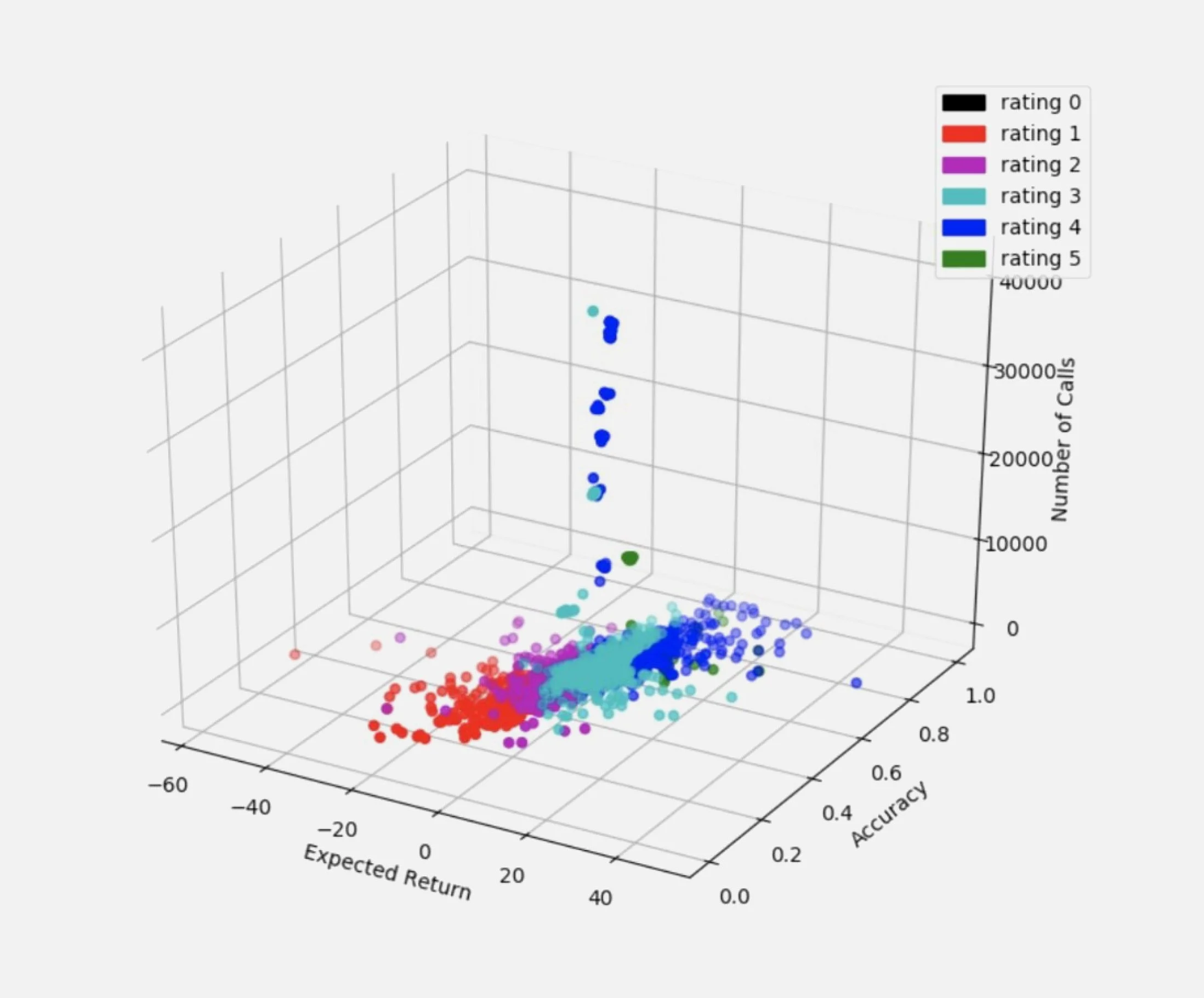
Nobias seeks to devise a statistically sound method for rating financial authors and analysts. For every author, there are 3 fields: the total number of calls made, accuracy, and expected return. All were collected by keeping track of articles they have published (LexisNexis live feed), determining the stock they were discussing (regex-like checks), determining the positive/negative slant in the way they discussed the stock to generate a buy/sell/neutral slant, and then checking during the 3 months that follow whether the slope of the stock price was in fact aligned with his recommendation and yielded a profit (or a loss) as well as the maximum loss observed. The expected return is based on the purchase of $100 worth of shares on the day of his prediction (this may be fractional), and the total average return after holding the stock for a specified time period (3 months in our first case). Accuracy, Expected return, and Maximum Loss are averaged across all calls. In the case of analysts, we allow for a longer (1 year) time frame or until the Price Target recommended by the Analyst is achieved or the Analyst revises his recommendation.